前言
今天的內容會接續昨天,所以如果還沒看過前一篇的可以先去看一下[Day24]不可不知的小工具-string.Length。昨天有提到我要匯入資料的時候,在程式面端就已經丟出exception了。今天的前提假設是程式碼端已經通過檢核,要進入寫入資料庫端的階段了。
註: 使用的是T-SQL
一樣先來認識下面幾個東西
NVARCHAR(n)
先來看看微軟文件的說明
可變大小字串資料。 n 會定義字串大小 (以位元組配對為單位),可以是 1 到 4,000 的值。 max 表示儲存體大小上限是 2^31-1 個字元 (2 GB)。 儲存大小是 n 位元組的兩倍 + 2 位元組。 針對 UCS-2 編碼,儲存大小是 n 位元組的兩倍 + 2 位元組,而可存放的字元數目也是 n。 針對 UTF-16 編碼,儲存大小仍是 n 個位元組的兩倍 + 2 個位元組,但可儲存的字元數目可能小於 n
謎之音:你最好是看得懂微軟文件在說什麼????
簡單來說,nvarchar(max)可以儲存大約21億多個字元,也就是說nvarchar(max)大約可以存21億多個字母/標點符號...等。如果套用到昨天的情境來說,nvarchar(500)可以儲存的大小就是1002個位元組,但可能會少於500個字元。順帶一提,SQL Server預設的編碼方式為UTF-16
UTF-16編碼
- 儲存資料時需要2個位元組(btye)
在 ASCII 的範圍之上,幾乎所有拉丁語系字集,以及希臘文、斯拉夫、科普特文、亞美尼亞文、希伯來文、阿拉伯文、敘利亞文、它拿文和西非書面文字在 UTF-8 和 UTF-16 中的每個字元都需要 2 個位元組。 在這些案例中,可比較的資料類型 (例如使用 char 或 nchar) 沒有明顯的儲存差異。
若其內容大部分是東亞字集 (例如韓文、中文和日文),則在 UTF-8 中每個字元都需要 3 個位元組,UTF-16 中則為 2 個位元組。 使用 UTF-16 可提供儲存空間上的優勢。
如果關於nvarchar的內容有大致了解,就讓我們繼續看下去!
LEN()
再來看看微軟文件又說了什麼
傳回指定字串運算式的字元數,但尾端空格不算。
可以講人話嗎....???
意思就是說如果使用LEN()這個函式,會回傳這個字串的字母/符號/空白的數量,但是最後面的空格並不會被算進去。
DATALENGTH()
還是要再來看看微軟文件說了什麼
此函式會傳回用來代表任何運算式的位元組數目。
意思是說DATALENGTH()這個函式回傳的內容是位元數目,而不是字元數目。下面舉例讓大家瞭解一下
舉例
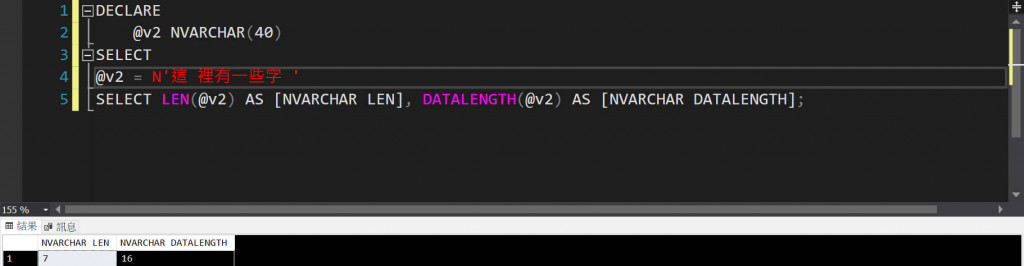
說明: 宣告一個變數,欄位大小開nvarchar(40)。變數內容裡面有6個中文字和2個空白(一個在中間一個在尾端)
用SSMS執行語法實際結果會是
LEN() => 7個字元,6個中文字加上中間一個空白
DATALENGTH() => 16個位元組, (6個中文字)2位元組 + (2個空白) 2位元組
講了這麼多,跟昨天的關聯又在哪裡了???讓我們繼續看下去
回歸正題
先附上我要存進資料庫的內容,已知這段越南文有627個字元,DATALENGTH()結果為1254。資料庫存放該內容的欄位大小是nvarchar(500)
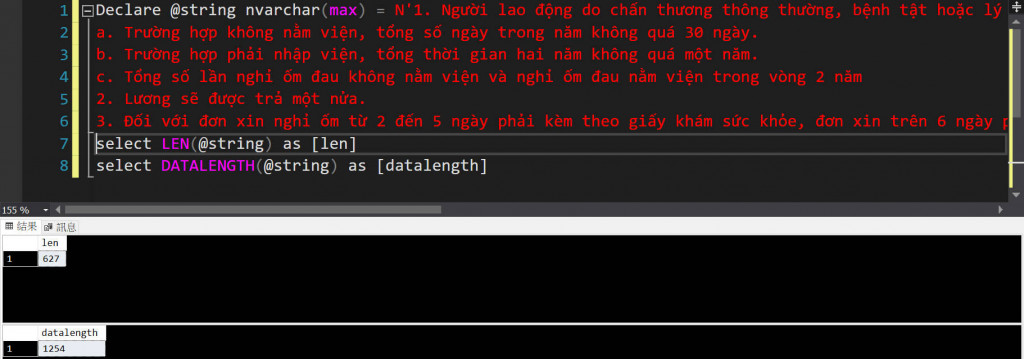
根據上面的內容,可以知道nvarchar(500)可以存的位元組大小為1002。所以真的要存進資料庫的話,這段內容也是會被截斷。不會完整的被存進資料庫內!
結論
沒有這次的踩雷經驗,真的是不會特別去搜尋這些資訊。找資料過程中還有看到UTF-16、UTF-8...編碼的形式也都會影響。希望這個分享可以幫助到大家~
參考
nchar 和 nvarchar (Transact-SQL)
LEN (Transact-SQL)
DATALENGTH (Transact-SQL)

 & DATALENGTH()_元件介紹-Day02 #註冊元件的手法_@suihsilan_https://static.coderbridge.com/images/covers/default-post-cover-1.jpg)

 & DATALENGTH()_【隨堂筆記】Python 資料處理_@fiona90178_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)

 & DATALENGTH()_Leetcode #1 Two Sum 解題_@loucadgarbon_https://static.coderbridge.com/img/loucadgarbon/54510587eb1f4ab4865bb34d789431ed.png)
